1. Overview
GAStech is a company that is located in a country island of Kronos and it has come to their attention that some of the employees had mysteriously went missing. Vehicles tracking data that was secretly installed in the company’s cars and Kronos-Kares benefit card information are delivered to authorities for investigation. We are tasked to used these information to identity patterns, anomolies or suspicious information that can be used to assist the kidnapping of GAStech employees.
2. Literature review of existing analysis performed
VAST challenges: Mini Case 2 was previously attempted back in 2014. There is a slight differences in the data given, such that credit card/Loyalty card records has Employees namein 2014 case and the revised mini case 2 in 2021 was not given any personal information in the card details. Therefore, it requires more cleaning and wrangling of data to infer the owners of the credits cards.
There are numerous people who attempted the challenges in 2014 and some are awarded with special honorary segment. However, if we take a look at their reports at VAST challenges Benchmark Repository, most of their work are not reproducible. Most of their designs and charts are either generated using JAVA or SAS enterprise. Therefore, without any code guidance and additional knowledge of coding, it is a steep learning curve in order to reproduce what they presented in their papers.
One of the advantage of using R markdown to attempt this challenges is that I have gained certain knowledge in R programming from classes. R studio is a solid platform to reproduce work as code chunks can be written and store in the program and code chunk can be displayed with a simple commend such as echo=TRUE to reflect them when knitting the project.
3. Extracting, wrangling and preparing the input data
3.1 Setting up environment
packages = c('tidyverse', 'lubridate', 'dplyr', 'raster', 'clock', 'sf', 'tmap',
'plotly','ggplot2', 'mapview', 'rgdal','rgeos', 'tidyr')
for (p in packages) {
if (!require(p, character.only = T)) {
install.packages(p, repos = "http://cran.us.r-project.org")
}
library(p, character.only = T)
}
3.2 Importing Employee’s Info and Car Assignment
carAssignment <- read_csv("mc2/car-assignments.csv")
carAssignment
# A tibble: 44 x 5
LastName FirstName CarID CurrentEmploymentT… CurrentEmploymentT…
<chr> <chr> <dbl> <chr> <chr>
1 Calixto Nils 1 Information Techno… IT Helpdesk
2 Azada Lars 2 Engineering Engineer
3 Balas Felix 3 Engineering Engineer
4 Barranco Ingrid 4 Executive SVP/CFO
5 Baza Isak 5 Information Techno… IT Technician
6 Bergen Linnea 6 Information Techno… IT Group Manager
7 Orilla Elsa 7 Engineering Drill Technician
8 Alcazar Lucas 8 Information Techno… IT Technician
9 Cazar Gustav 9 Engineering Drill Technician
10 Campo-Corr… Ada 10 Executive SVP/CIO
# … with 34 more rows3.3 Import Credit card and Loyalty card data
ccData <- read_csv("MC2/cc_data.csv")
ccData$timestamp = date_time_parse(ccData$timestamp, zone = "", format = "%m/%d/%Y %H:%M")
ccData <- ccData %>%
mutate(date = as.Date(ymd_hms(timestamp)), time = strftime(timestamp, "%H:%M"), hr = strftime(timestamp, "%H"))
loyaltyData <- read_csv("MC2/loyalty_data.csv") %>%
mutate(date = as.Date(mdy(timestamp)))
ccLoyalty <- left_join(ccData, loyaltyData, by = c("date", "location", "price")) %>%
dplyr::select(timestamp.x, date, time, location, price, last4ccnum, loyaltynum, hr) %>%
rename(timestamp = timestamp.x) %>%
group_by(last4ccnum)
ccLoyalty$weekday = wday(ccLoyalty$date, label = TRUE, abbr = TRUE)
ccLoyalty$last4ccnum = as.character(ccLoyalty$last4ccnum)
ccLoyalty$location <- gsub("[\x92\xE2\x80\x99]", "", ccLoyalty$location)
ccLoyalty$location <- gsub("[\xfc\xbe\x8e\x96\x94\xbc]", "e", ccLoyalty$location)
ccLoyalty
# A tibble: 1,496 x 9
# Groups: last4ccnum [55]
timestamp date time location price last4ccnum
<dttm> <date> <chr> <chr> <dbl> <chr>
1 2014-01-06 07:28:00 2014-01-06 07:28 Brew've Been… 11.3 4795
2 2014-01-06 07:34:00 2014-01-06 07:34 Hallowed Gro… 52.2 7108
3 2014-01-06 07:35:00 2014-01-06 07:35 Brew've Been… 8.33 6816
4 2014-01-06 07:36:00 2014-01-06 07:36 Hallowed Gro… 16.7 9617
5 2014-01-06 07:37:00 2014-01-06 07:37 Brew've Been… 4.24 7384
6 2014-01-06 07:38:00 2014-01-06 07:38 Brew've Been… 4.17 5368
7 2014-01-06 07:42:00 2014-01-06 07:42 Coffee Camel… 28.7 7253
8 2014-01-06 07:43:00 2014-01-06 07:43 Brew've Been… 9.6 4948
9 2014-01-06 07:43:00 2014-01-06 07:43 Brew've Been… 16.9 9683
10 2014-01-06 07:47:00 2014-01-06 07:47 Hallowed Gro… 16.5 8129
# … with 1,486 more rows, and 3 more variables: loyaltynum <chr>,
# hr <chr>, weekday <ord>3.4 Data cleaning
- Convert special characters in Katerina’s Cafe to “Katerinas Cafe”
- Index similar credit card and loyalty card to 1 employee through grouping
ccLoyalty$location <- gsub("[\x92\xE2\x80\x99]", "", ccLoyalty$location)
ccLoyalty$location <- gsub("[\xfc\xbe\x8e\x96\x94\xbc]", "e", ccLoyalty$location)
ccLoyalty_person <- ccLoyalty %>%
group_by(last4ccnum) %>%
distinct(loyaltynum) %>%
arrange(last4ccnum) %>%
filter(loyaltynum != 'NA')
ccLoyalty_person$ccPerson <- ccLoyalty_person %>% group_indices(last4ccnum)
lcard <- ccLoyalty %>%
group_by(loyaltynum) %>%
distinct(last4ccnum) %>%
arrange(loyaltynum)
new <- merge(ccLoyalty_person, lcard, by="loyaltynum") %>%
arrange(ccPerson)
lookup <- new %>%
select(ccPerson, last4ccnum.y) %>%
arrange(ccPerson) %>%
distinct(last4ccnum.y, .keep_all = TRUE)
xdata <- inner_join(new, lookup, by=c("ccPerson", "last4ccnum.y")) %>%
arrange(ccPerson)
# reassign an id to be in running order
xdata$personId <- xdata %>% group_indices(ccPerson)
3.5 Mapping credit cards and loyalty card
A single employee can carries multiple credit cards and loyalty cards Match the data created in 3.4 to the transaction data based on credit card to that each transaction is mapped to an id
ccLoyalty_merge <- left_join(ccLoyalty, xdata, by=c("last4ccnum"="last4ccnum.y")) %>%
select(personId, timestamp, weekday, timestamp, date, time, location, price, last4ccnum, loyaltynum.x, hr) %>%
arrange(personId) %>%
distinct()
ccLoyalty_merge
# A tibble: 1,496 x 10
# Groups: last4ccnum [55]
personId timestamp weekday date time location
<int> <dttm> <ord> <date> <chr> <chr>
1 1 2014-01-06 08:16:00 Mon 2014-01-06 08:16 Brew've Been…
2 1 2014-01-06 12:00:00 Mon 2014-01-06 12:00 Jack's Magic…
3 1 2014-01-06 13:27:00 Mon 2014-01-06 13:27 Abila Zacharo
4 1 2014-01-06 19:50:00 Mon 2014-01-06 19:50 Frydos Autos…
5 1 2014-01-07 07:54:00 Tue 2014-01-07 07:54 Brew've Been…
6 1 2014-01-07 12:00:00 Tue 2014-01-07 12:00 Jack's Magic…
7 1 2014-01-07 13:24:00 Tue 2014-01-07 13:24 Kalami Kafen…
8 1 2014-01-07 20:15:00 Tue 2014-01-07 20:15 Ouzeri Elian
9 1 2014-01-08 08:16:00 Wed 2014-01-08 08:16 Brew've Been…
10 1 2014-01-08 12:00:00 Wed 2014-01-08 12:00 Jack's Magic…
# … with 1,486 more rows, and 4 more variables: price <dbl>,
# last4ccnum <chr>, loyaltynum.x <chr>, hr <chr>3.6 Importing GPS
- Converting Timestamp to “Year-Month-Day Hour:Minutes” (YYYY-MM-DD HH:MM) format
- Separate Timestamp into 2 new columns (Date & Time)
- Converting data type for id to factor
gps <- read_csv("MC2/gps.csv") %>%
mutate(date = as.Date(mdy_hms(Timestamp)), time = format(mdy_hms(Timestamp), "%H:%M"))
gps$Timestamp <- date_time_parse(gps$Timestamp, zone = "", format = "%m/%d/%Y %H:%M:%S")
gps$hr <- strftime(gps$Timestamp, "%H")
gps$id <- as_factor(gps$id)
gps$weekday <- wday(gps$date, label = TRUE, abbr = TRUE)
gps
# A tibble: 685,169 x 8
Timestamp id lat long date time hr
<dttm> <fct> <dbl> <dbl> <date> <chr> <chr>
1 2014-01-06 06:28:01 35 36.1 24.9 2014-01-06 06:28 06
2 2014-01-06 06:28:01 35 36.1 24.9 2014-01-06 06:28 06
3 2014-01-06 06:28:03 35 36.1 24.9 2014-01-06 06:28 06
4 2014-01-06 06:28:05 35 36.1 24.9 2014-01-06 06:28 06
5 2014-01-06 06:28:06 35 36.1 24.9 2014-01-06 06:28 06
6 2014-01-06 06:28:07 35 36.1 24.9 2014-01-06 06:28 06
7 2014-01-06 06:28:09 35 36.1 24.9 2014-01-06 06:28 06
8 2014-01-06 06:28:10 35 36.1 24.9 2014-01-06 06:28 06
9 2014-01-06 06:28:11 35 36.1 24.9 2014-01-06 06:28 06
10 2014-01-06 06:28:12 35 36.1 24.9 2014-01-06 06:28 06
# … with 685,159 more rows, and 1 more variable: weekday <ord>3.7 Car coordinates when vehicle stopped
I am eliminating coordinates that indicating that the car is moving The GPS car coordinates are recorded every 1-5 secs. Therefore, if there is a GPS record difference of more than 5 min, which means the employee has driven the car to a destination. Thus this eliminates possible traffic light stops and car moving in motion data.
For each employee: 1. I am getting the first and last car coordinate each day 2. Getting places of interest through the day
ts <- gps %>%
group_by(id) %>%
arrange(date, time, by_group=TRUE) %>%
mutate(diff = round(c(difftime(tail(Timestamp, -1), head(Timestamp, -1), units = "mins"), 0)), 2) %>%
mutate(count = 1:n(), FIRST = count == 1, LAST = count == max(count)) %>%
filter(diff > 5 | FIRST == TRUE | LAST == TRUE) %>%
arrange(id) %>%
select(id, lat, long, date, time, diff, hr, weekday, Timestamp)
ts
# A tibble: 3,133 x 9
# Groups: id [40]
id lat long date time diff hr weekday
<fct> <dbl> <dbl> <date> <chr> <drtn> <chr> <ord>
1 1 36.1 24.9 2014-01-06 07:20 0 mins 07 Mon
2 1 36.1 24.9 2014-01-06 07:22 35 mins 07 Mon
3 1 36.0 24.9 2014-01-06 08:04 253 mins 08 Mon
4 1 36.1 24.9 2014-01-06 12:26 59 mins 12 Mon
5 1 36.0 24.9 2014-01-06 13:34 250 mins 13 Mon
6 1 36.1 24.9 2014-01-06 17:48 108 mins 17 Mon
7 1 36.1 24.9 2014-01-06 19:42 7 mins 19 Mon
8 1 36.1 24.9 2014-01-06 19:49 38 mins 19 Mon
9 1 36.1 24.9 2014-01-06 20:33 98 mins 20 Mon
10 1 36.0 24.9 2014-01-06 22:15 46 mins 22 Mon
# … with 3,123 more rows, and 1 more variable: Timestamp <dttm>3.8 Setting up the map of Abilas, Kronos
OGR data source with driver: ESRI Shapefile
Source: "/Users/yuntinghong/Documents/SMU/ISSS608 - Visual Analytics/hongyunting/YTBlog_ISSS608/_posts/2021-07-20-assignment-mc2/MC2/Geospatial", layer: "Abila"
with 3290 features
It has 9 fields
Integer64 fields read as strings: TLID 4. Insights and Observations
Question 4.1
Using just the credit and loyalty card data, identify the most popular locations, and when they are popular. What anomalies do you see? What corrections would you recommend to correct these anomalies?
| Observation | Supporting Evidence |
|---|---|
| Figure 1 shows that “Katerina’s Cafe” is identified as the popular location as it has the highest number of transaction made within these 2 weeks, followed by “Hippokampos” and “Guy’s Gyros”. | 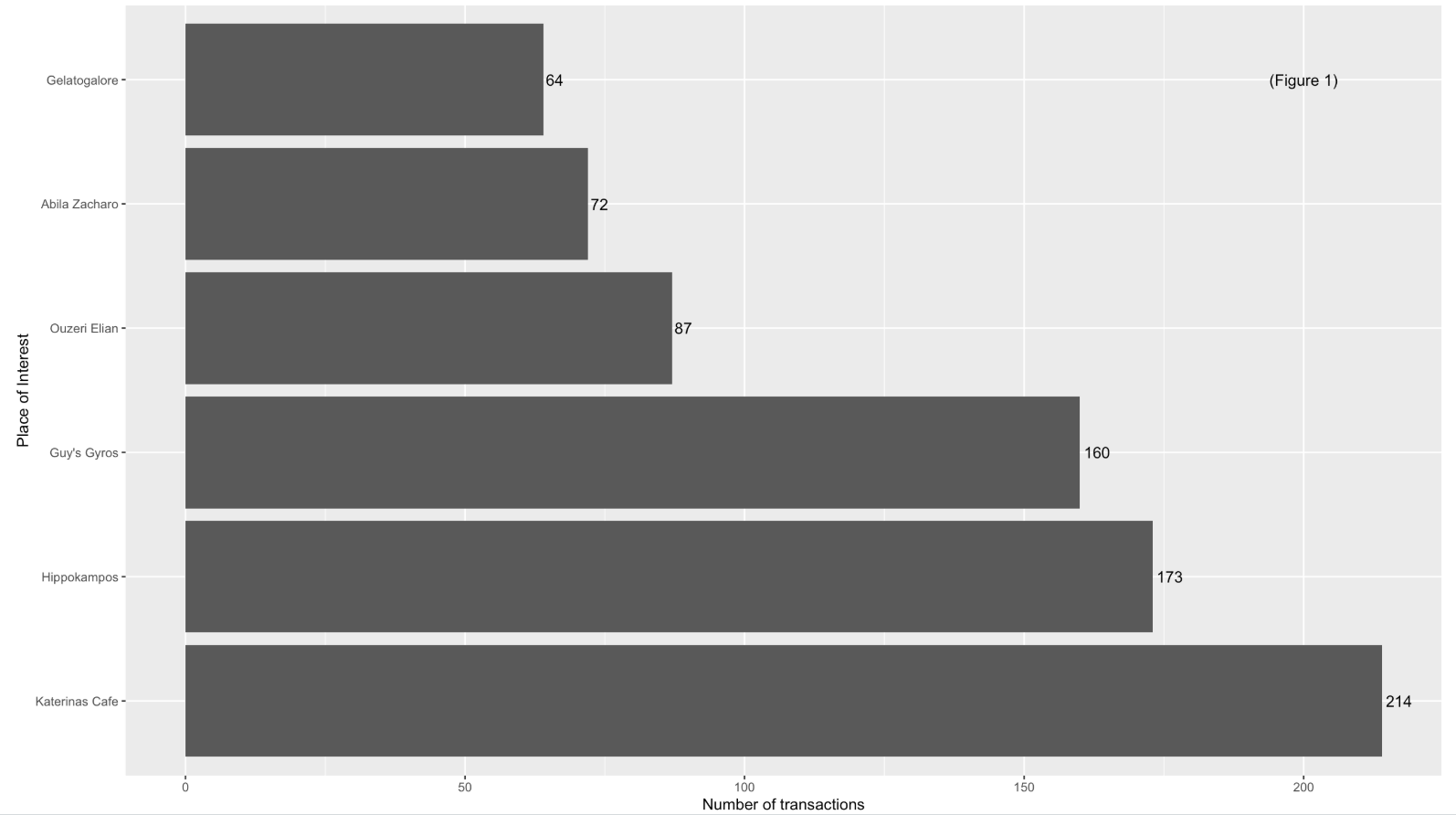 |
| Figure 2 shows that “Abila Zacharo” attracts more than 80% of GAStech employees who are entitled a company car. | 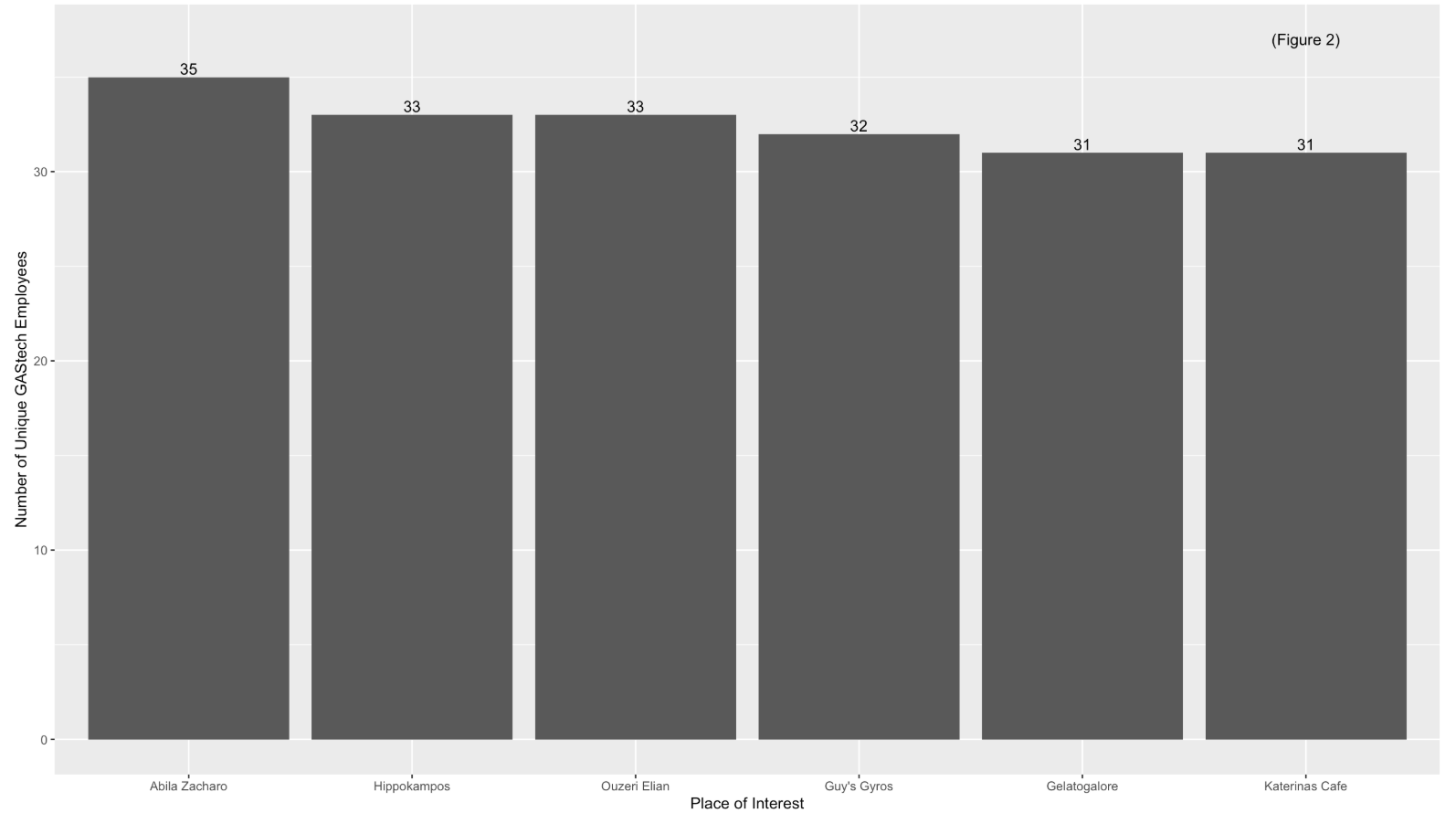 |
| Figure 3 and 4 indicates that during Monday to Friday (Working day) and between 7am to 8am, the most frequented locations are Food & Beverage outlets, namely “Brew’ve Been Served” where employees go out for lunch or buy a cup of coffee for their breakfast and most of the employees head over “Katerina’s Cafe” at night, probably for dinner. | 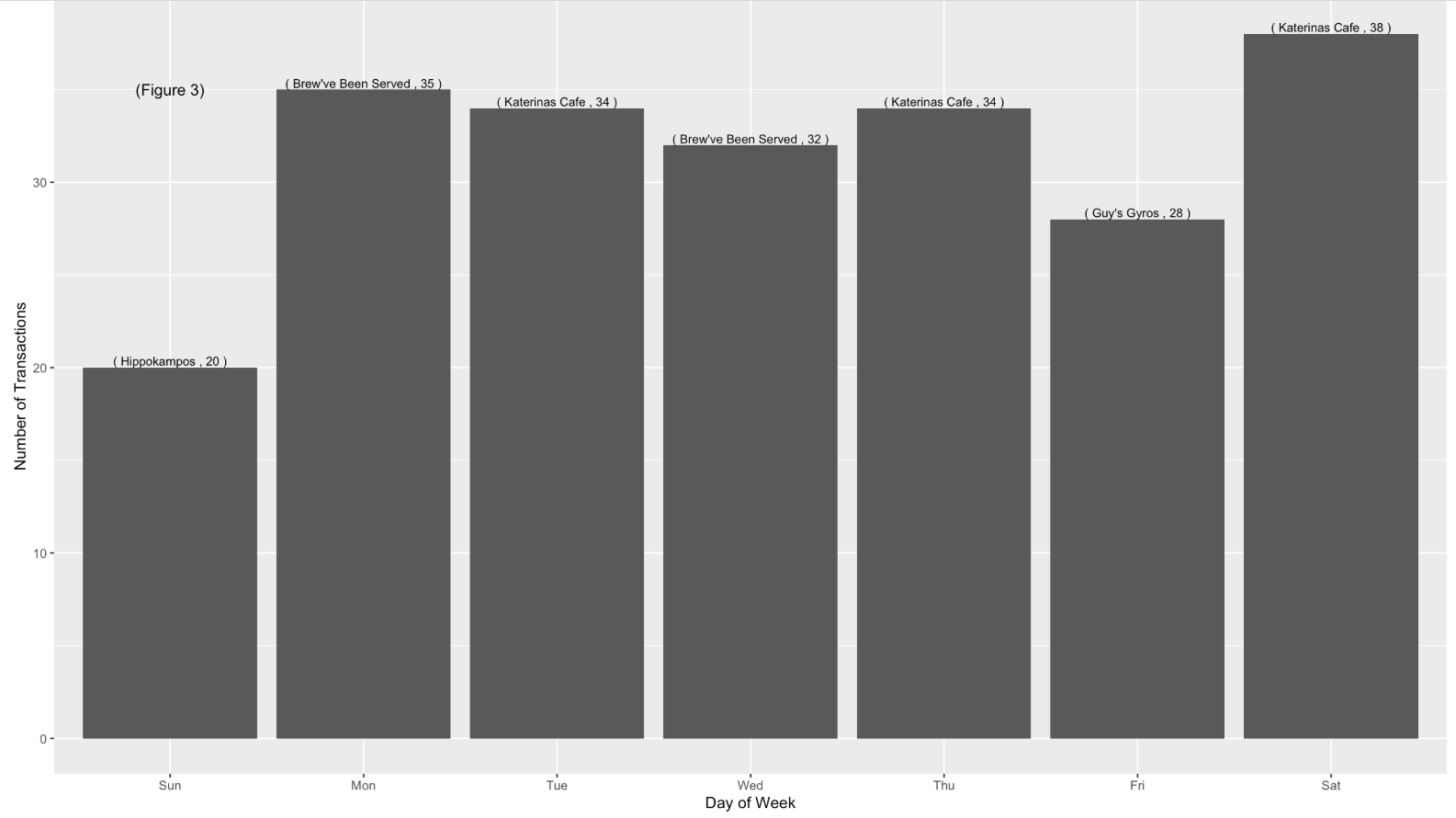 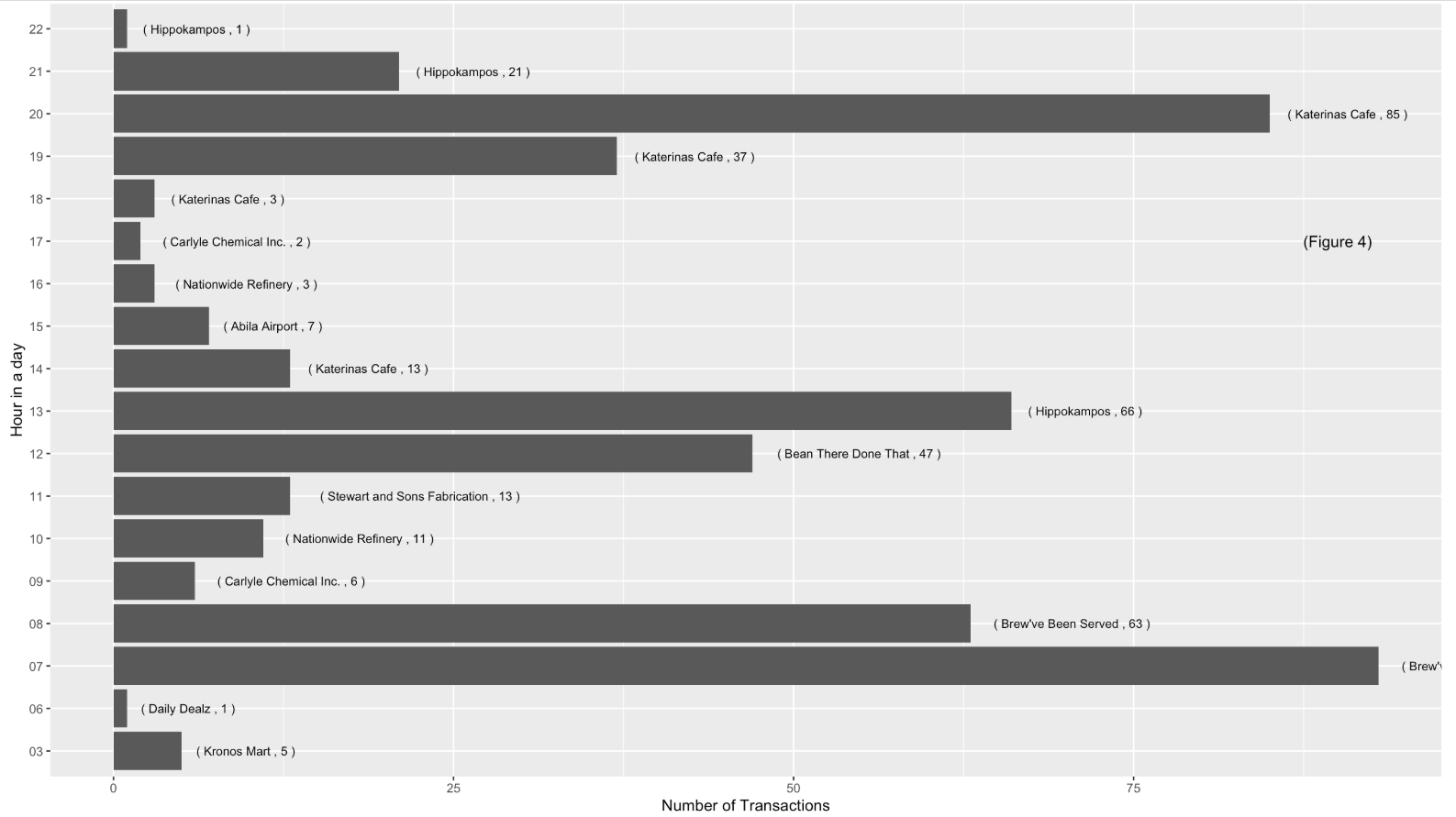 |
| However, based on the credit card and loyalty card record, only 30 employees left at least 1 transaction trail. | |
| Assumptions was made while cleaning credit card and loyalty card transaction. 1 employee carries multiple credit cards and loyalty card. |
ccLoyalty_merge$personId <- as_factor(ccLoyalty_merge$personId)
test <- ccLoyalty_merge
test$date <- as.Date(test$date)
test$time <- as.POSIXct(format(test$time, zone="", format = "%H:%M"), format = "%H:%M")
p <-ggplot(test, aes(date, time)) +
geom_jitter(aes(group = personId, color = personId)) +
scale_y_datetime(date_breaks = "1 hour", date_labels = "%H") +
scale_x_date(date_breaks = "1 day", date_labels="%d")
fig <- ggplotly(p)
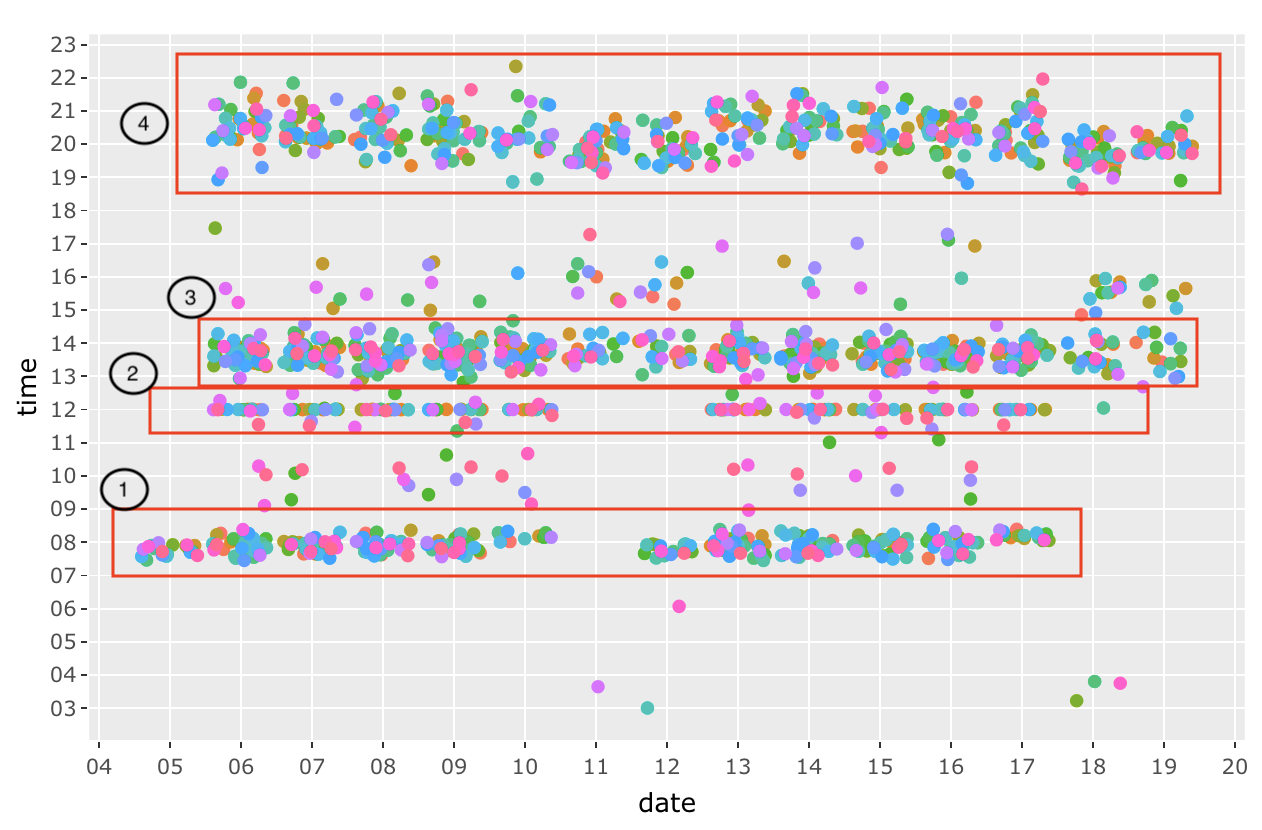
The figure above shows the transactions of all the GAStech employees across these 2 weeks. We can established a pattern of their purchases such as Morning breakfast (7am to 9am), Lunch time at 12pm, late lunch or breaks from 1pm to 3pm and dinner time from 7pm to 10pm.
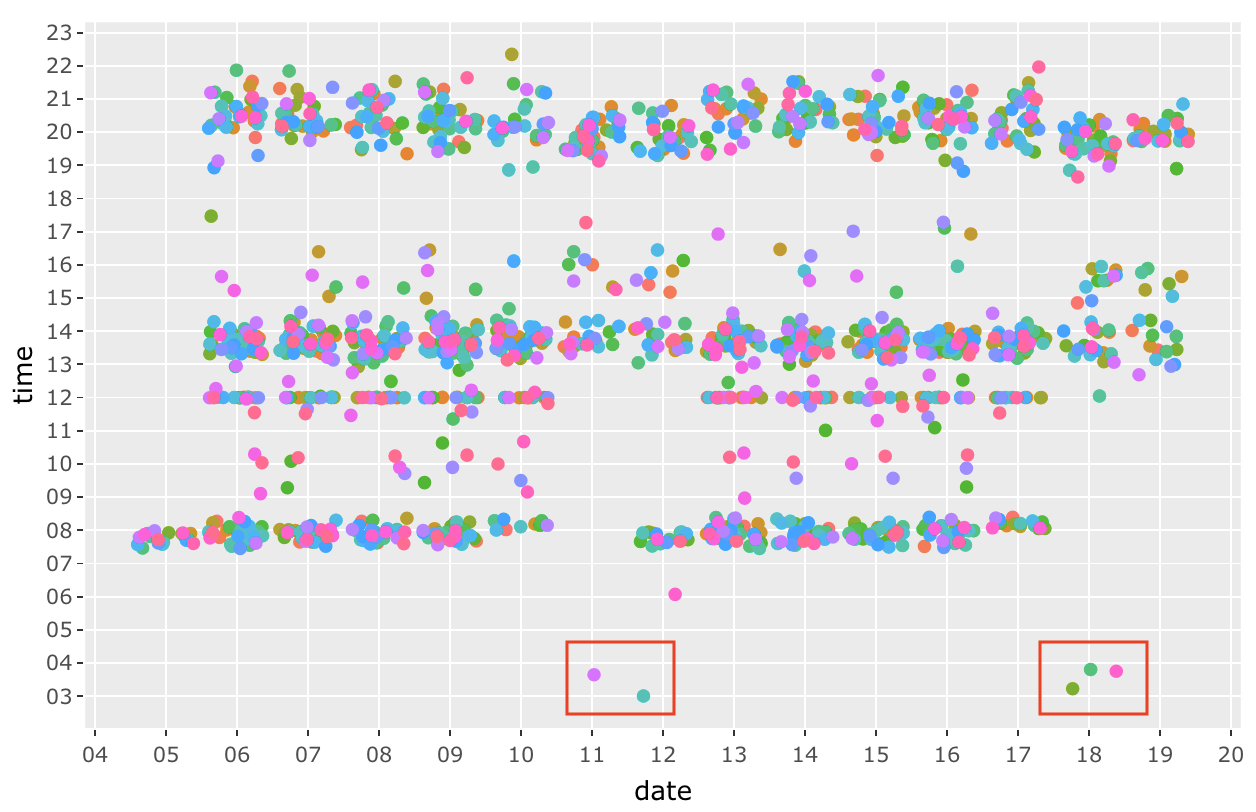 There are a few anomalies (outliers) such as the dots from 3am to 6am. Especially during 18 January 2014, 3 transactions are made within 30 mins of each other.
There are a few anomalies (outliers) such as the dots from 3am to 6am. Especially during 18 January 2014, 3 transactions are made within 30 mins of each other.
Question 4.2
Add the vehicle data to your analysis of the credit and loyalty card data. How does your assessment of the anomalies in question 1 change based on this new data? What discrepancies between vehicle, credit, and loyalty card data do you find? Please limit your answer to 8 images and 500 words.
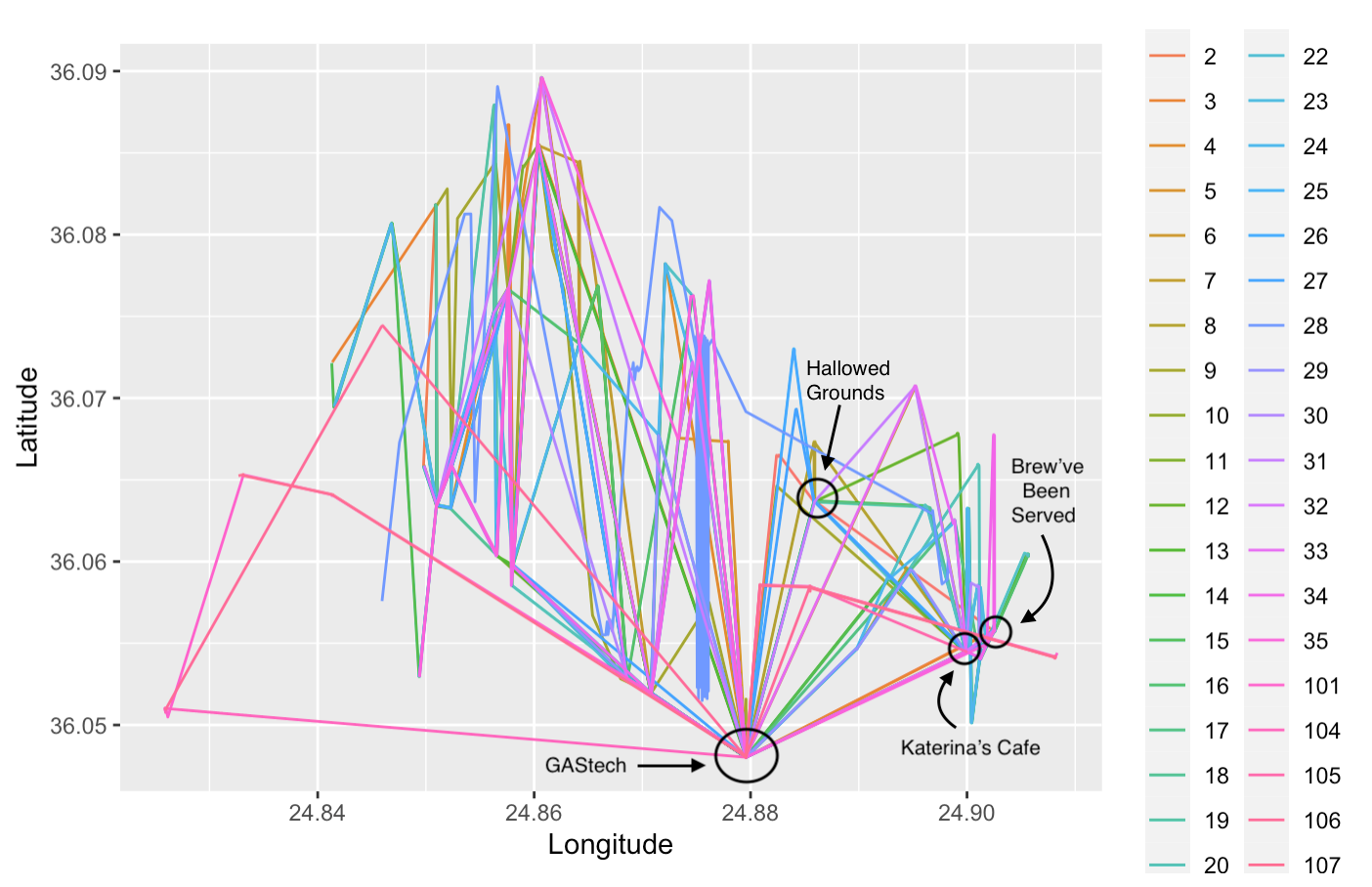
Each end point of a straight line in Figure X represent that an employee has stopped at a location for a long duration of more than 5 mins over 2 weeks. This shows some of the popular location such as “Brew’ve Been Served”, “Katerina’s Cafe” and “Hallowed Grounds”
Question 4.3
Can you infer the owners of each credit card and loyalty card? What is your evidence? Where are there uncertainties in your method? Where are there uncertainties in the data? Please limit your answer to 8 images and 500 words.
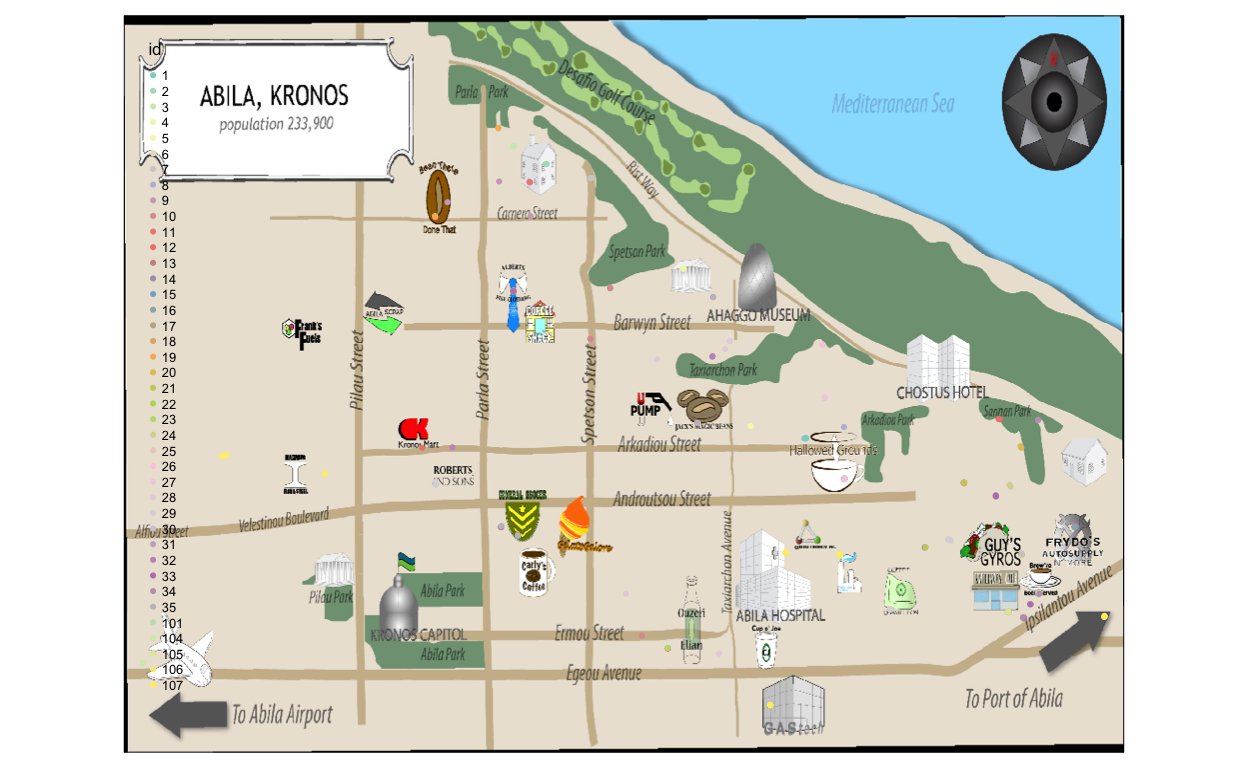
Since we are aware of the popular areas from Question 4.1, these are the locations that is overcrowded with data points. Therefore, the trick to identify the owners to the credit card and loyalty card is by narrowing down the scope to unpopular locations, such as “U-Pump”, “Golf Course” and “Abila Airport”.
For Example: 1. There are only 2 transaction made at U-Pump on 2014-01-06; one of them is at 1:18pm, the other is at 5:28pm. Based on the GPS locations on that day, Car 23 and Car 24 had made a stop at U-Pump at 5:12pm for 18 mins and at 12:35 for 47 mins respectively.

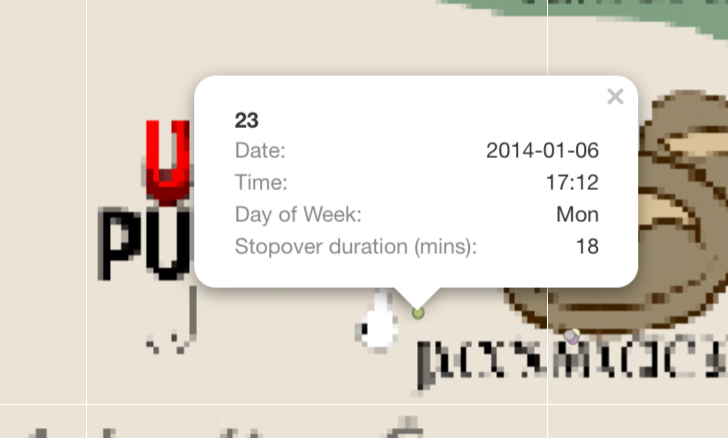
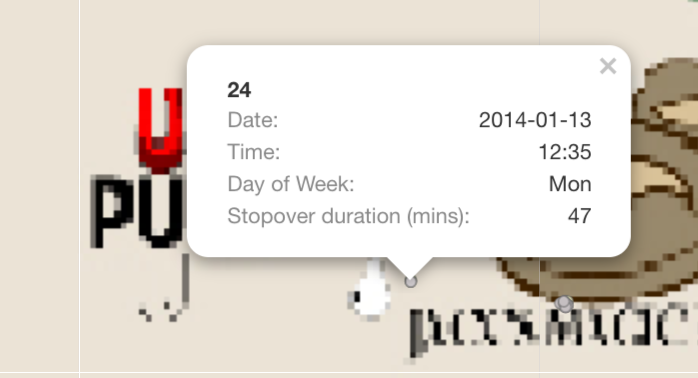
- The next location that I used to infer, is “Abila Airport” and I filtered out a single day “2014-01-09”. There are a total of 5 GPS location record at “Abila Aiport” and 4 credit card transactions made.
- 3 records of truck ID 104 at 10:51am (For 24 mins), 11:16am (For an hour), 1:09pm (For 2.7 hours)
- 1 record of truck ID 101 at 8:29am (For 58 mins)
- 1 record of truck ID 106 at 12:37pm (For 41 mins)
Using the above vehicles information, I can infer that: - personId 8 in CC data is truck ID 106 - personId 15 in CC data is truck ID 101 - personId 41 in CC data is truck ID 104



However, this method may creates loopholes such as if credit card is stolen and used by someone else, it will tend to mislead us that the employee made a purchase but in fact he/she didn’t. The data is missing information on employee personal details with the credit card or loyalty card data. Through data cleaning, we understand that each employee can have multiple credit card and multiple loyalty card, there are bound to be mislinked data.
Question 4.4
Given the data sources provided, identify potential informal or unofficial relationships among GASTech personnel. Provide evidence for these relationships. Please limit your response to 8 images and 500 words.
| Relationship | Supporting Evidence |
|---|---|
| 1. Car ID 7 and 33 seems to have a romantic relationship. On 8th and 14th, Car ID 7 and 33 checked into Chostus Hotel on a Wednesday brunch hour 11am for a minimum of 1hr 40 mins on both occasions. |  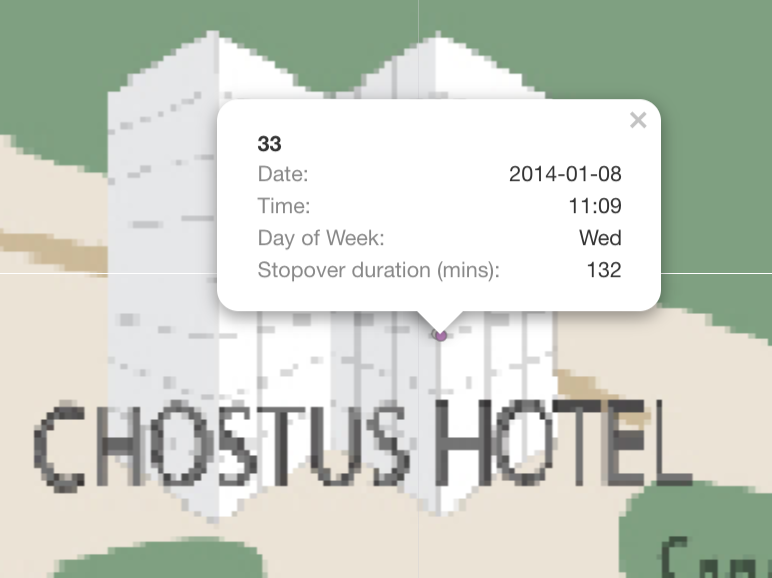 |
| 2. Car 4 and Car 10 are Golf buddy. On 2 occasions, 12th and 19th, they stopped by Desafio Gold Course at 12:30pm, for 2.5 hours and 1pm, for 3 hours respectively. | 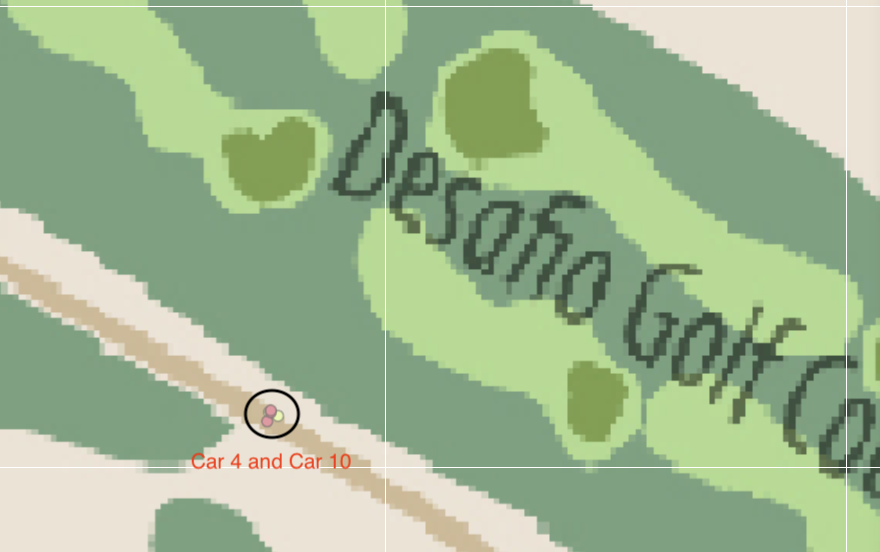 |
| 3. Engineering team has a after work gathering session on 10th at Car 2 house. Car ID 2,3,5,11,19,18,25,26 and 33 is there. | 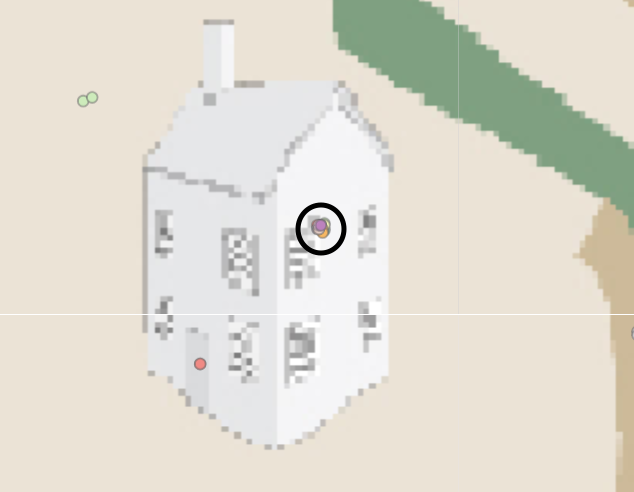 |
Question 4.5
Do you see evidence of suspicious activity? Identify 1- 10 locations where you believe the suspicious activity is occurring, and why Please limit your response to 10 images and 500 words.
| Suspicious Activities | Support Evidence |
|---|---|
| 1. On 9th, Truck Driver 107 stop by Abila Hospital and GPS tracking states that he have stopover for at least 17 hours. |  |
| 2. Car 4 is often seen hanging around courtyard. He has more than 10 GPS records indicating he stop by for long period each time. | 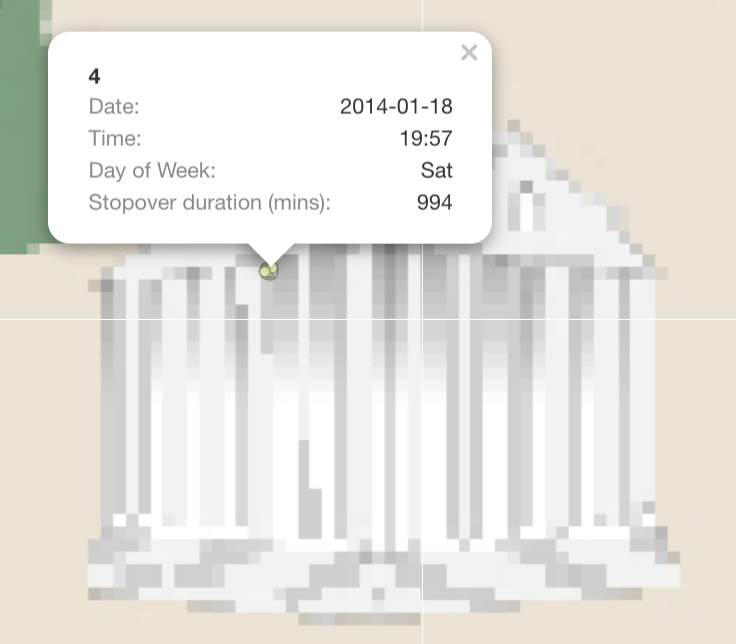 |
| 3. I believe Car 17, 24, 33 has a certain relationship. They are always staying and leaving from the same location on multiple occasion, with a few mins apart from each other. However, there is no house icon on the maps that indicates it is a residential area. | 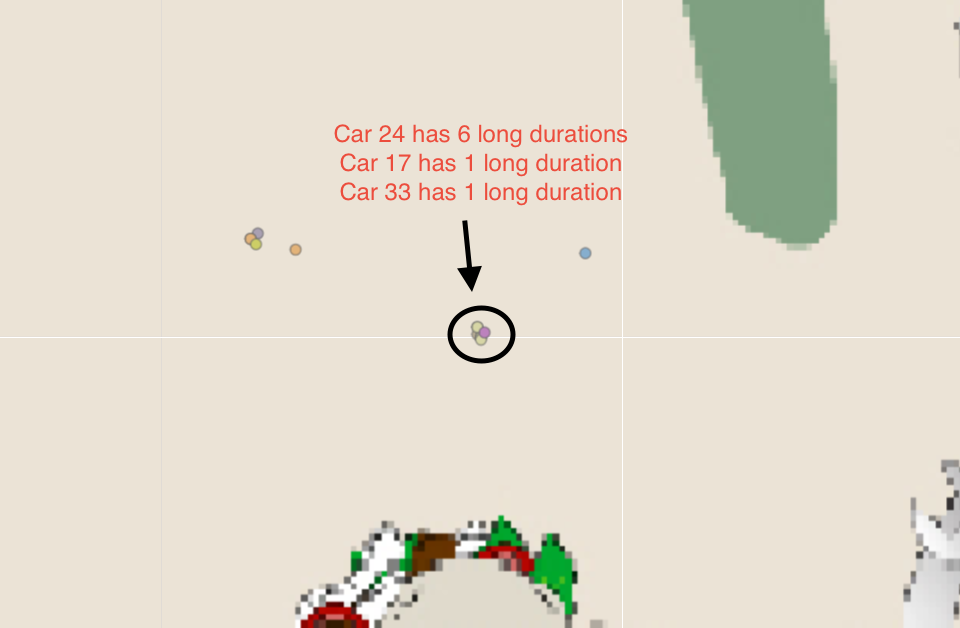 |
| 4. I believe Car ID 14 and 18 had the same behaviour as No.3. They always have stopover GPS records together on multiple occasions | 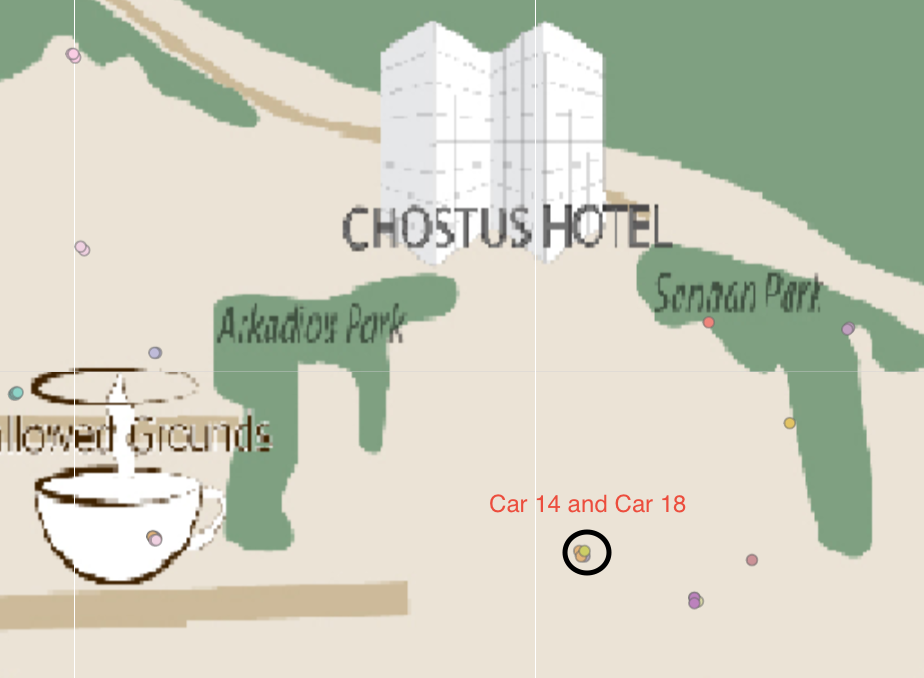 |
| 5. Car 24 stopped at Taxiarchon Park on 8th at 11:53pm and stayed for 3 hours. It is weird that someone will head over to a park in the middle of the night | 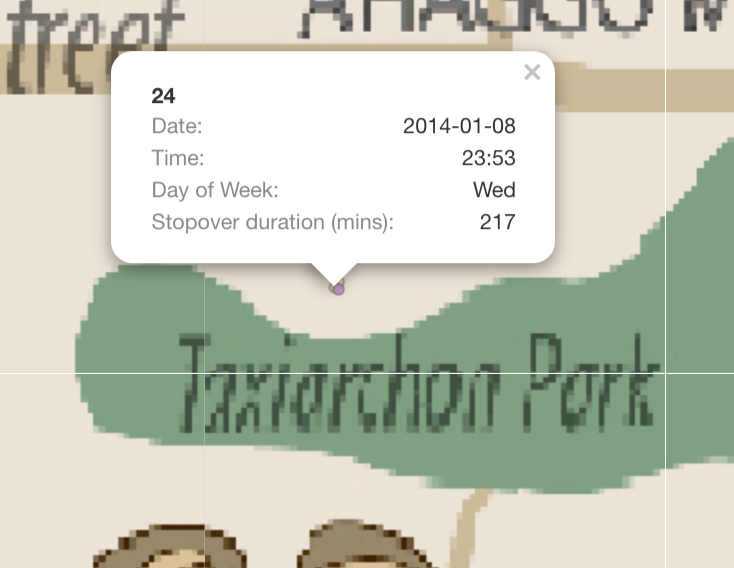 |